Nathan Lambert , 2026-01-07 15:07:00
Starting 2026, most people are aware that a handful of Chinese companies are making strong, open AI models that are applying increasing pressure on the American AI economy.
While many Chinese labs are making models, the adoption metrics are dominated by Qwen (with a little help from DeepSeek). Adoption of the new entrants in the open model scene in 2025, from Z.ai, MiniMax, Kimi Moonshot, and others is actually quite limited. This sets up the position where dethroning Qwen in adoption in 2026 looks impossible overall, but there are areas for opportunity. In fact, the strength of GPT-OSS shows that the U.S. could very well have the smartest open models again in 2026, even if they’re used far less across the ecosystem.
The following plots are from a comprehensive update of the data supporting The ATOM Project (atomproject.ai) with our expanded ecosystem measurement tools we use to support our monthly open model roundups, Artifacts Log.
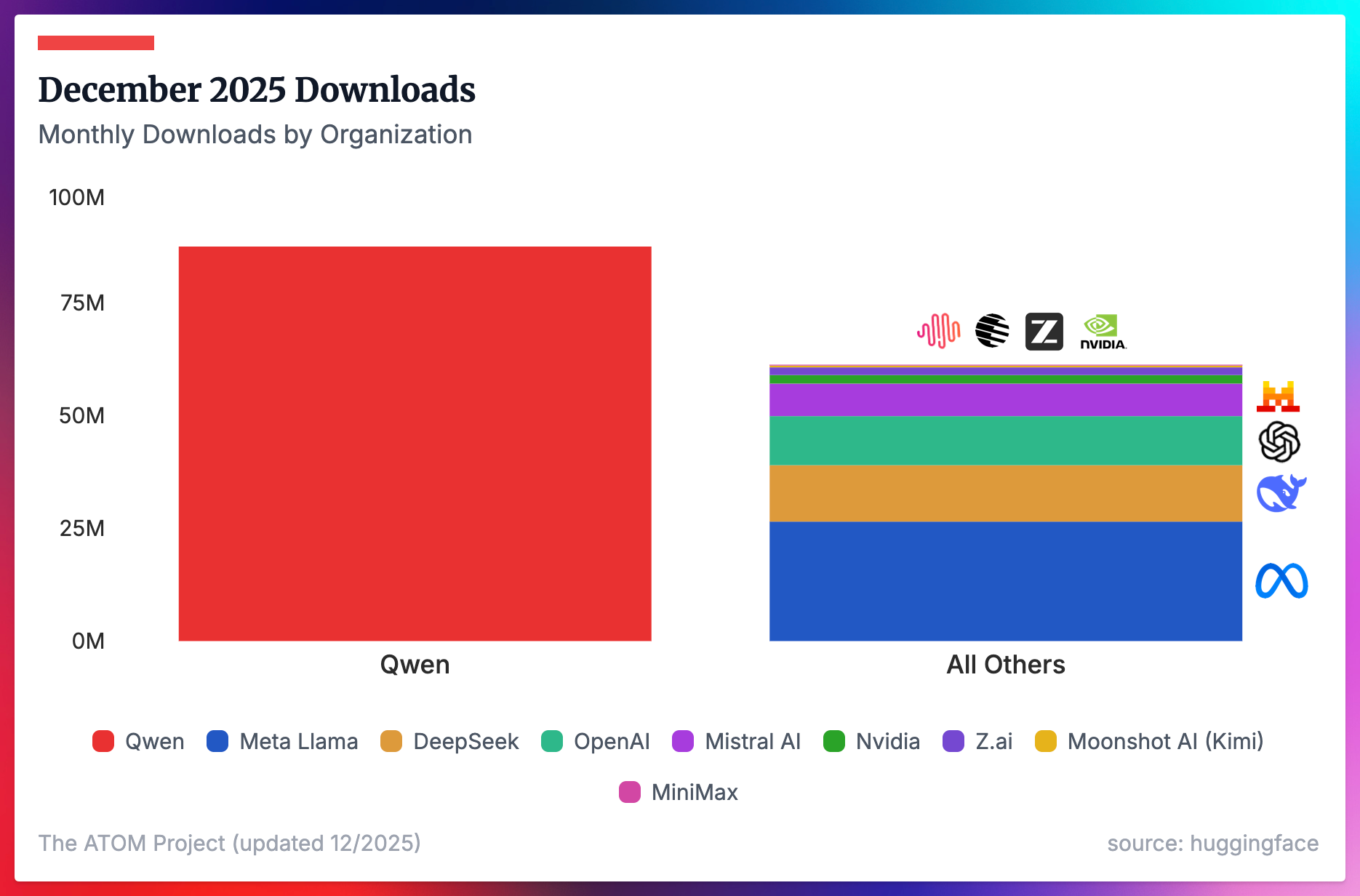
Models from the US and the EU defined the early eras of open language models. 2025 saw the end of Llama and Qwen triumphantly took its spot as the default models of choice across a variety of tasks, from local LLMs to reasoning models or multimodal tools. The adoption of Chinese models continues to accelerate.
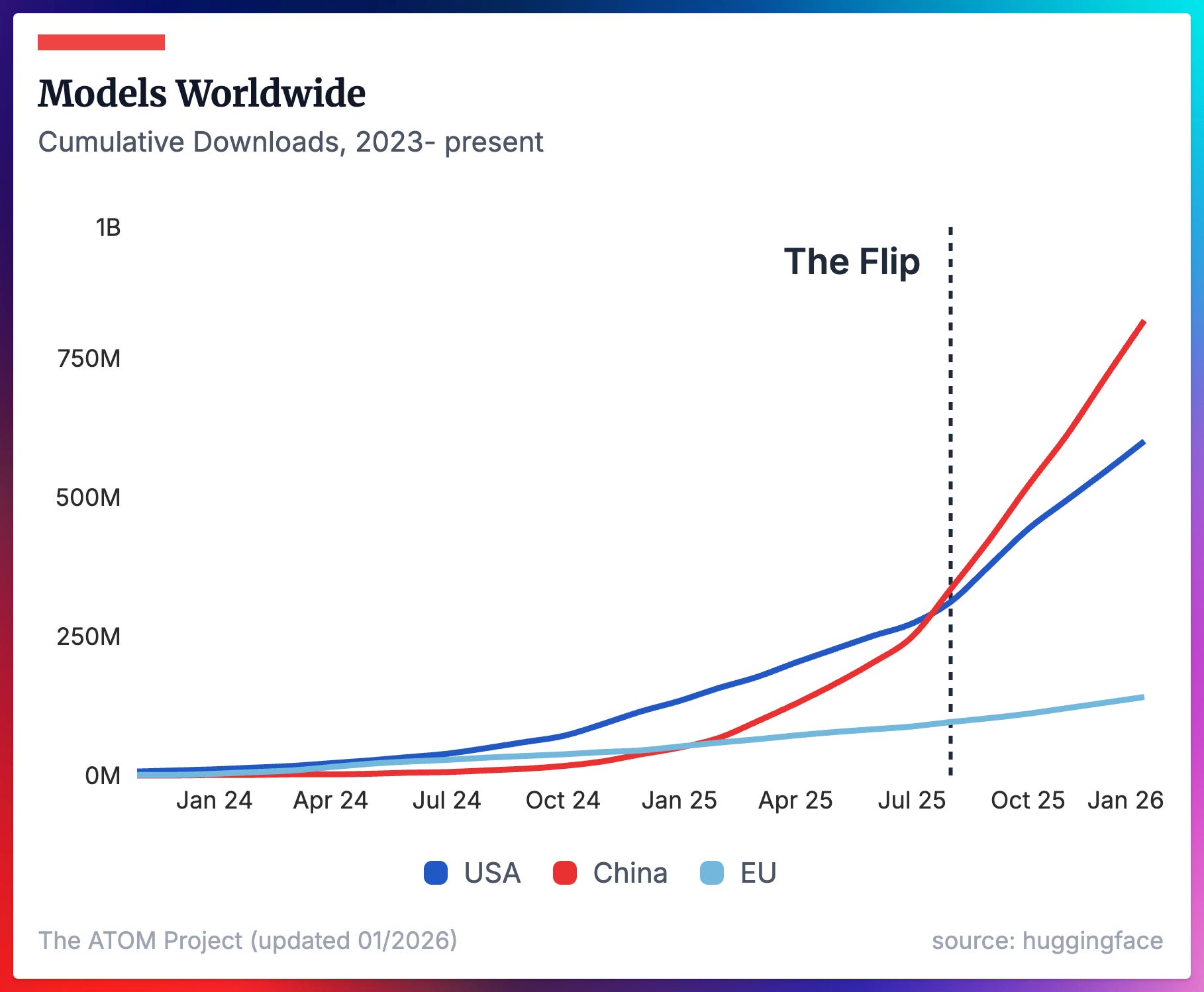
These first two plots show the cumulative downloads of all LLMs we consider representative of the ecosystem (we’re tracking 1152 in total right now), which were released after ChatGPT.
Where we’ve seen China’s lead increase in overall downloads in the previous figure, it feels increasingly precarious for supporters of Western open models to learn that Llama models — despite not being updated nor supported by their creator Meta — are still by far the most downloaded Western models in recent months. OpenAI’s GPT-OSS models are the only models from a new provider in the second half of 2025 that show early signs of shifting the needle on the balance of overall downloads from either an American or Chinese provider (OpenAI’s two models get about the same monthly downloads at the end of 2025 as all of DeepSeek’s or Mistral’s models).
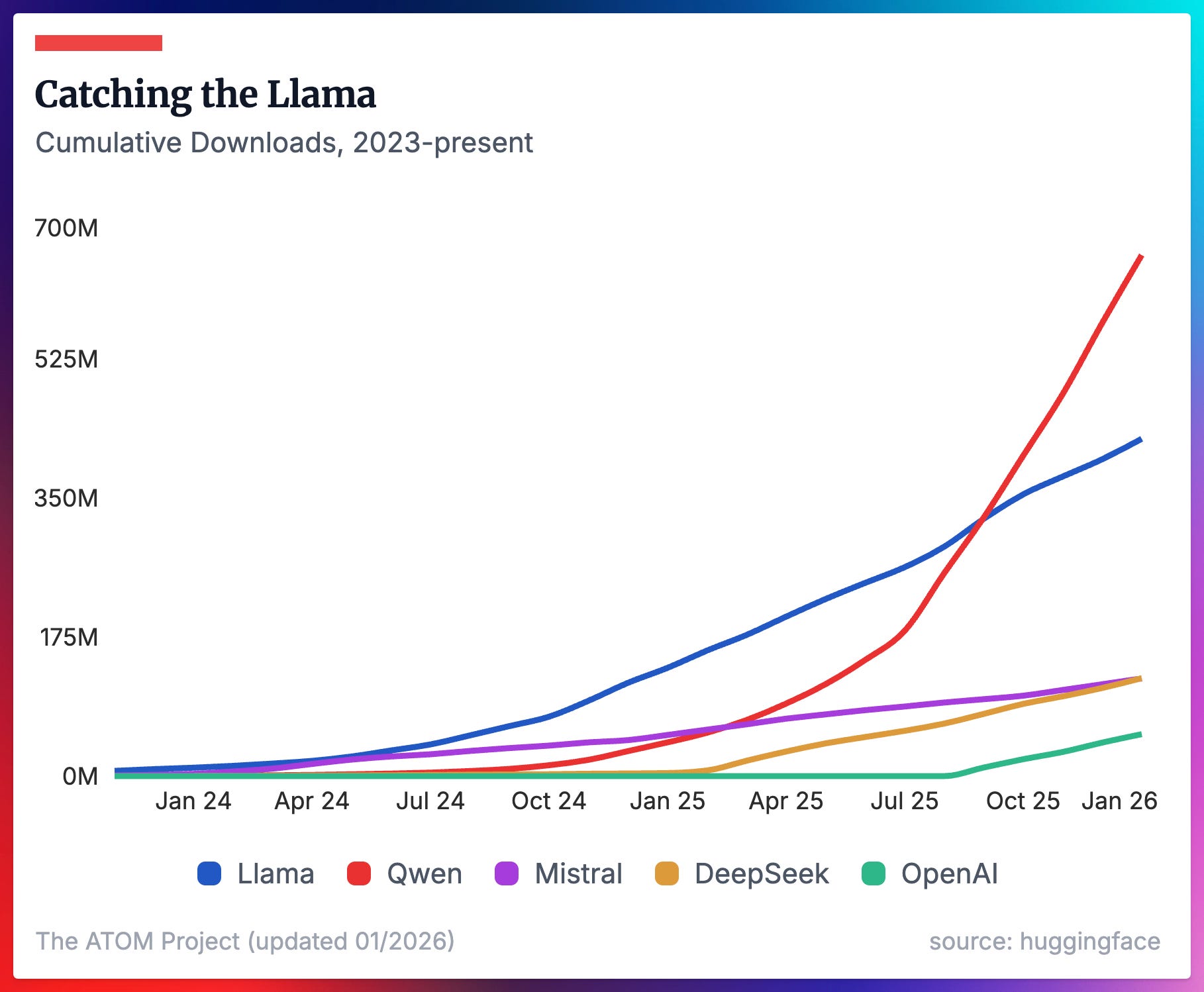
What is a HuggingFace download? HuggingFace registers a download for any web request to the storage buckets to the model (e.g. wget, curl, etc.), so it is a very noisy metric. Still, it’s the best we have. Due to this noise, when measuring adoption via how many finetunes a model has, we filter to derivative models with only >5 downloads. Still, downloads are the standard way of measuring adoption of open models.
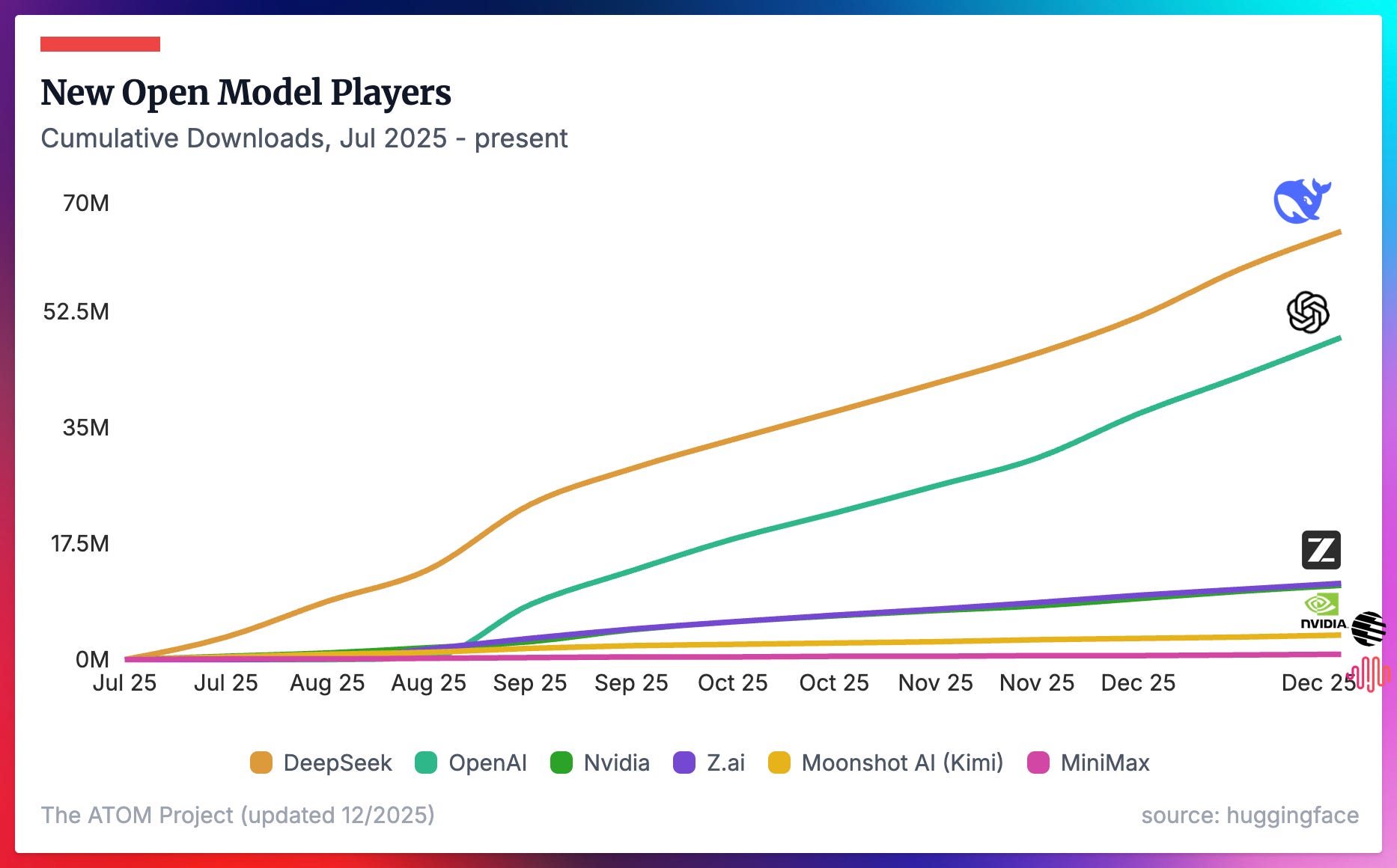
While much has been said (including by me, on Interconnects) about new open frontier model providers, their adoption tends to look like a rounding error in adoption metrics. These models from Z.ai, Nvidia, Kimi Moonshot, and MiniMax are crucial to developing local ecosystems, but they are not competing with Qwen as being the open model standard.
Note the different y-axes from this plot and the previous, where DeepSeek and OpenAI are included in both for scale. This plot shows the downloads just since July 2025 to showcase recent performance.
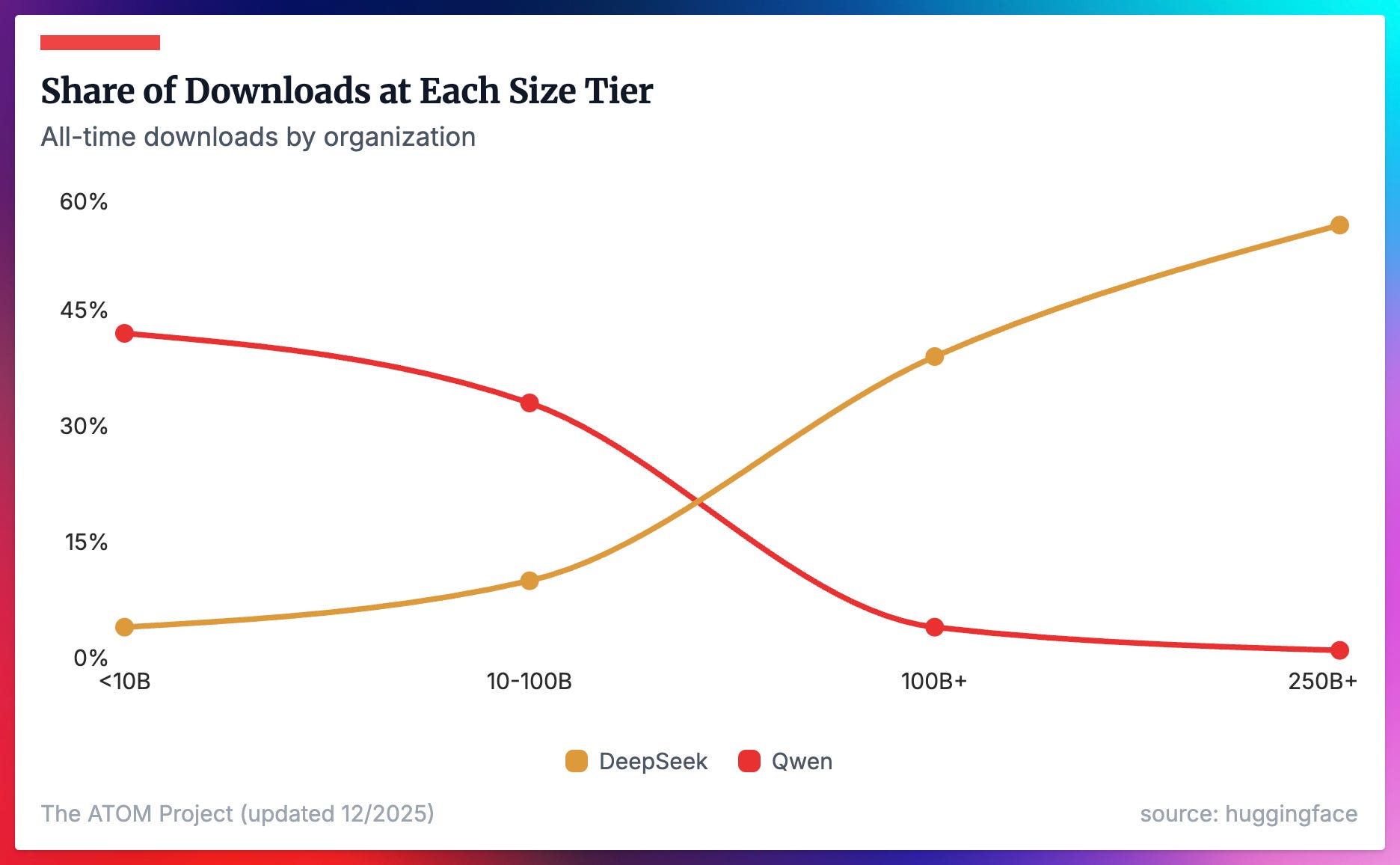
One of the most surprising things in the data is just how successful DeepSeek’s large models are (particularly both versions of V3 and R1). These 4 large models dominate the adoption numbers of any of Qwen’s large MoE/dense models over the last few years. It’s only at these large scales where opportunities to compete with Qwen exist, and with the rise of more providers like Z.ai, MiniMax, and Kimi, we’ll be following this closely. These large models are crucial tools right now for many startups based in the U.S. trying to finetune their own frontier model for applications — e.g. Cursor’s Composer model is finetuned from a large Chinese MoE.
While Qwen has one Achilles’ heel right now, its recent models totally dominate any HuggingFace metric. If we look at the top 5 Qwen3 downloaded models just in December (Qwen3-[0.6B, 1.7B, 4B (Original), 8B, & 4B-Instruct-2507]), they have more downloads than all of the models we’re tracking from OpenAI, Mistral AI, Nvidia, Z.ai, Moonshot AI, and MiniMax combined.
This is the advantage that Qwen has built and will take year(s) to unwind.
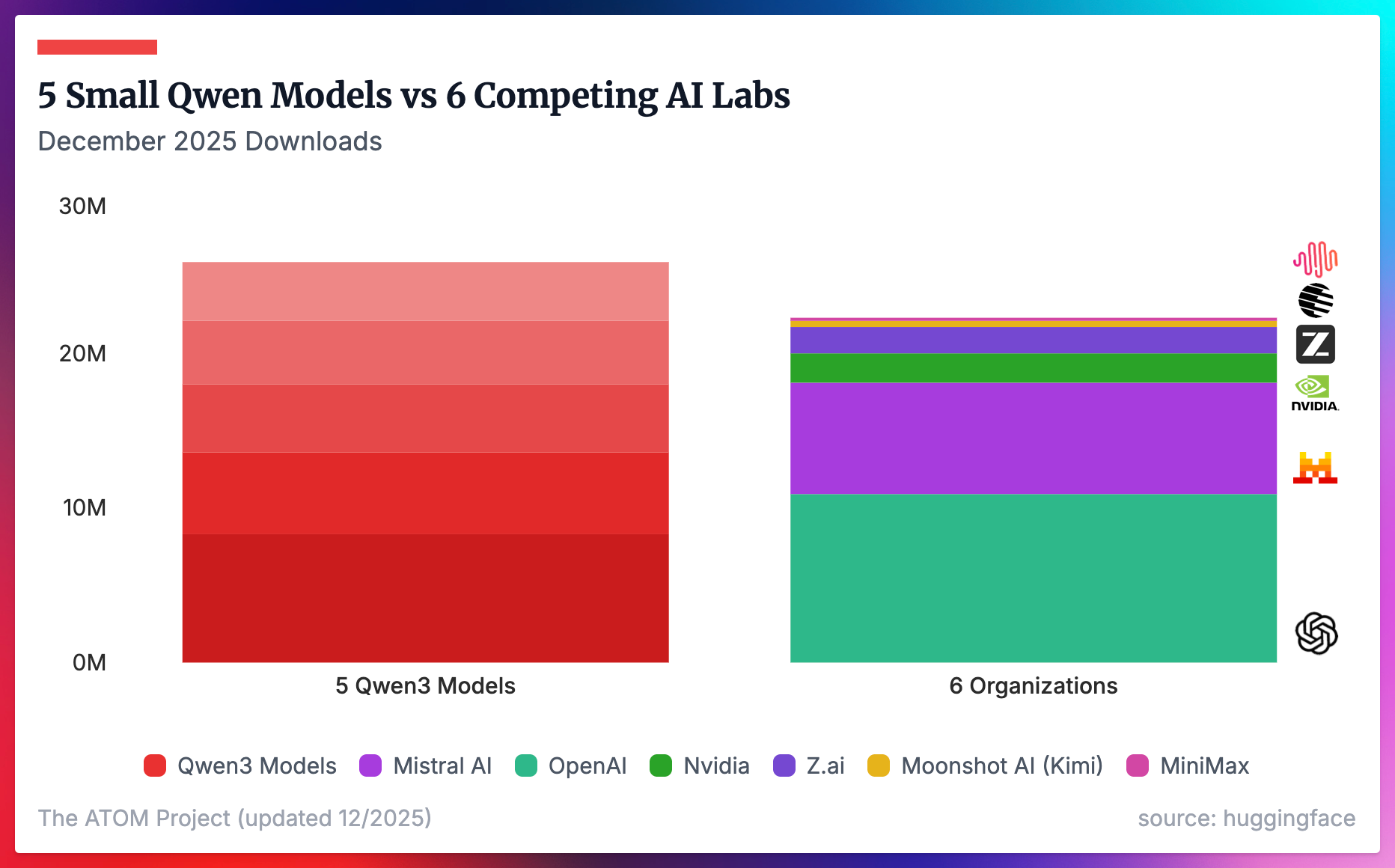
If we account for every meaningful Qwen LLM released since ChatGPT, the downloads Qwen got in December well outnumber literally every other organization we’re tracking combined. This includes the 6 from the previous figure, along with DeepSeek and Meta, who are the second and third most downloaded creators.
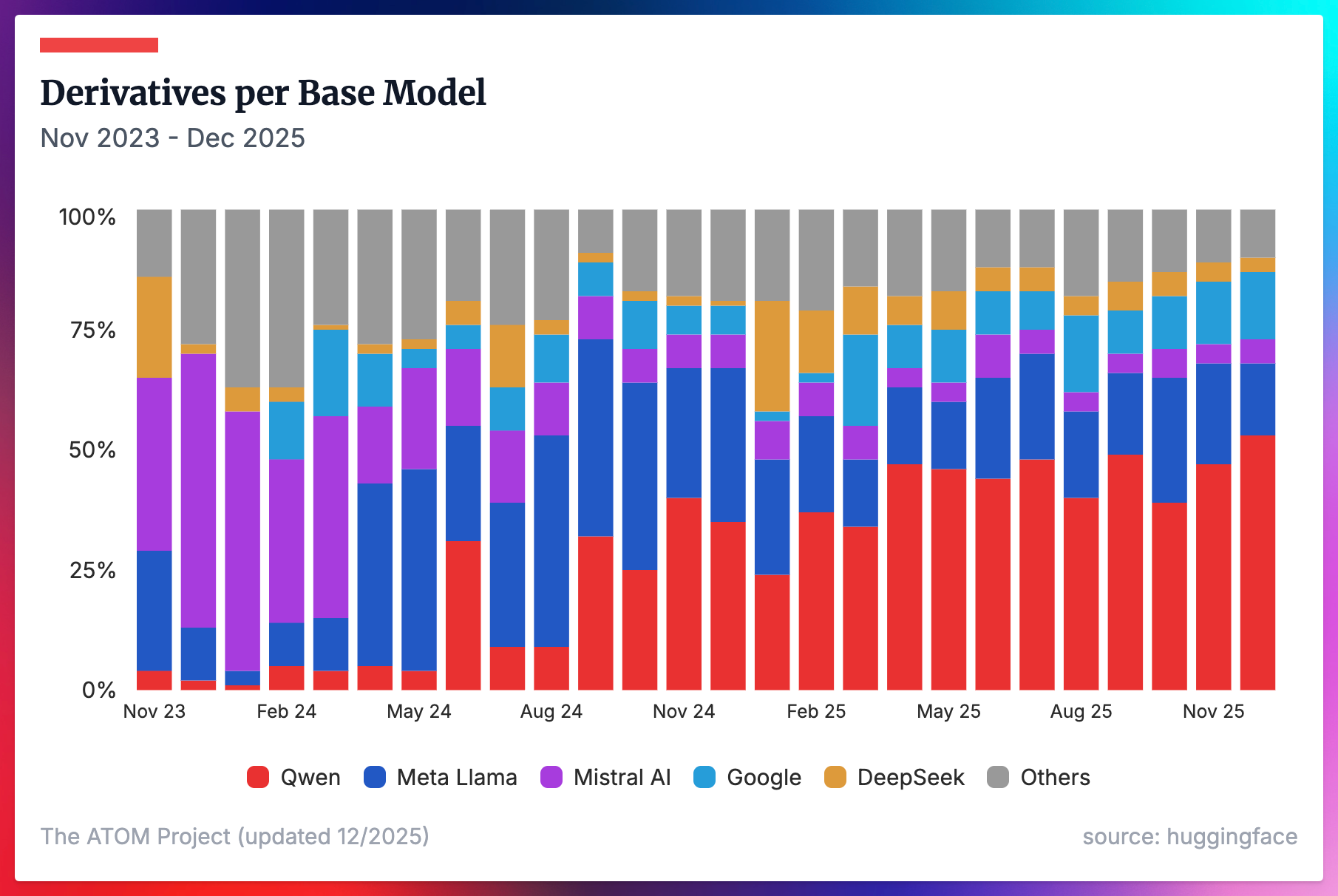
The other primary way we can measure Qwen’s adoption lead is to look at the share of derivative models on HuggingFace (filtered to only those with >5 downloads to indicate a meaningful finetune) that come from a certain base model. Qwen’s share here continued to grow throughout 2025, and we’ll be watching this closely around the likely release of Qwen 4.
Despite the dramatic increase in the number of players releasing open models in 2025, the share of finetuned models has concentrated among the 5 organizations we highlighted below (Qwen, Llama, Mistral, Google, and DeepSeek).
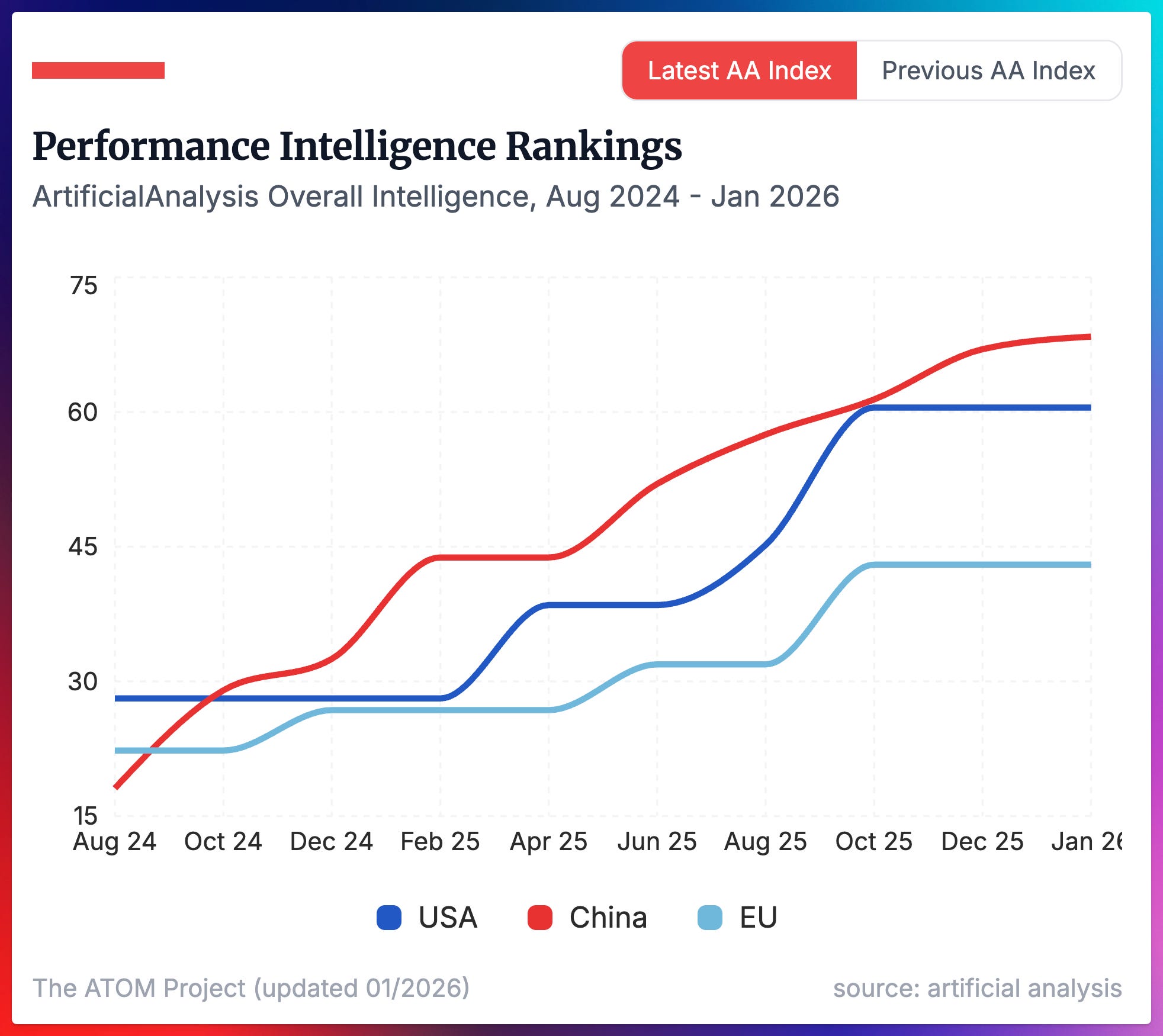
The primary factor that drives the adoption and influence of Chinese open models today is that they’re the smartest open models available. There’s a variety of second order issues, such as licenses, model sizes, documentation, developer engagement, etc., but for over a year now, Chinese open models have been the smartest on most benchmarks.
GPT-OSS 120B was close to retaking the lead (slightly behind MiniMax M2), but it wasn’t quite there. It’ll be fascinating to watch if upcoming Nemotron, Arcee, or Reflection AI models can buck this trend. If you look at other metrics than the Artificial Analysis intelligence index, the same trends hold.
Thanks for reading! Please reach out or leave a comment if there’s a corner of the data you think we should spend more time in. Stay tuned for more updates on The ATOM Project and related efforts in the near future.
