This study is part of the Artificial Intelligence in Mammography Screening (AIMS) study. The AIMS study protocol was approved by East Midlands Nottingham Research Ethics Committee (no. 22/EM/0038) and NHS England Breast Screening Programme Research Advisory Committee (no. BSPRAC_0093). The study was registered with the ISRCTN (no. 60839016). The AIMS study was funded by a National Institute for Health and Care Research (NIHR) award from the Secretary of State for Health and Social Care. An overview of the study is given in Fig. 1a–e. Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Case selection
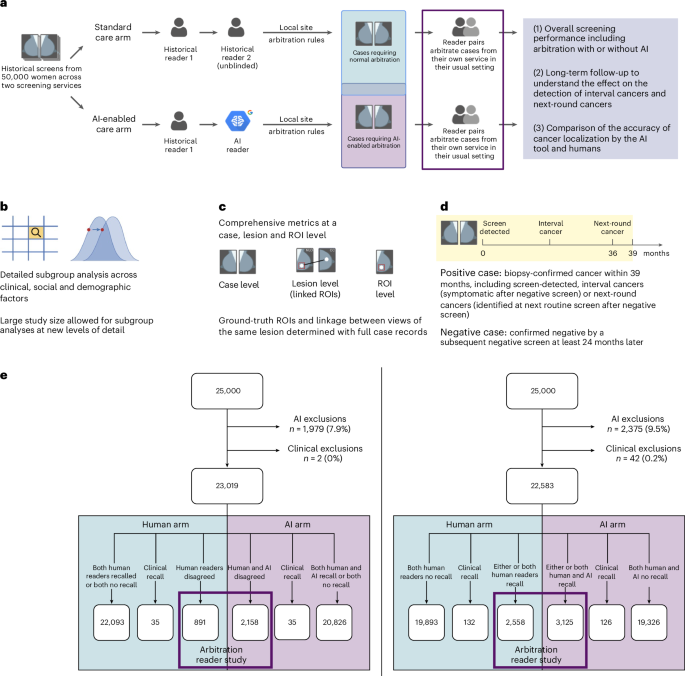
Mammography images and clinical data for 50,000 women from two NHSBSP screening centers were selected from the OPTIMAM Mammography Image Database OMI-DB11.
The AI developer had used 10,000 cases from each screening center to select the operating point or threshold that is optimal for the recall rate for the local center. The vendor advised that they would do this before clinical implementation at any NHSBSP screening centers and so this mimicked the clinical situation. Therefore, all episodes for these women from any year were removed before selection of the study dataset.
We randomly selected 25,000 women aged 50–70 years per screening center from 2016. This permitted a 3-year follow-up in 2019, to avoid any potential impact of COVID-19 on the data. At both screening centers, the interval cancers in the National Breast Screening System (NBSS) were lower than expected from the national Screening History Information Management system. Therefore, the additional interval cancers to reach the numbers reported by the Screening History Information Management system were selected from a wider year range: 2011–2018. There was a proportion of women with normal mammograms, but no subsequent normal mammogram to confirm the negative ground truth. To ensure a high-quality ground truth, women younger than 68 years with normal mammograms, but no subsequent screening episode, were replaced with women who did have a follow-up mammogram from a wider year range: 2011–2018. The women were matched by episode outcome, whether it was the first or the subsequent mammogram, and by age (for screening center 1 within ±1 year and for screening center 2 within ±3 years). Women aged 68+ years were permitted to have no follow-up screen, because they would not typically be invited back as part of national screening at this age. For screening center 2, there was also a proportion of women whose cases had been used to train the AI tool. These were also replaced with women who had not been used to train the AI tool, with the same matching criteria as above.
The clinical data included pathological information and the recall or no-recall decisions by the historical first and second readers and arbitration. The locations of cancers for 94.5% of positive cases were recorded with a rectangle around the cancer or area where the cancer was later detected for those detected as interval cancers or at the next screening round. These bounding boxes were the ground-truth ROIs. For the remaining 5.5% of positive cases there were insufficient clinical data available for such annotation.
AI exclusion criteria were applied for technical recalls, any study containing >4 images or <4 images, or cases with implants, resulting in 4,354 women (8.7%) being excluded. The AI tool was run on the mammography images for the women not excluded and an AI recall decision for each woman was obtained using the site-specific operating points10. This included a case level decision and ROIs (bounding boxes marking suspicious areas). In addition, 44 (0.1%) cases were excluded due to insufficient or conflicting clinical information.
In the human arm of the study, the workflow was based on the recall decision of historical first and second human readers. In the AI arm of the study, the workflow was based on the recall decision of the first historical human reader and the AI tool. To determine the impact of the AI tool on arbitration, the arbitration criteria at each center were applied and selected cases read in a reader study with two readers making the arbitration decision. At center 1, women went to arbitration if, for either breast, there was a disagreement between the first and second readers. At center 2, women went to arbitration if recalled by either the first or second reader or both. A flowchart of the case selection, study exclusions and allocation to arms is given in Fig. 1e.
Design of arbitration reader study
AI system
The AI system used in this evaluation was created by Google (v1.2, Google LLC) and is an updated version of the v1.0 model9,10. This is an AI-powered, independent mammography reader product for double-read breast cancer-screening workflows. It analyses two-dimensional, full-field digital mammograms to give a normal or abnormal screening determination and highlights suspicious ROIs. The AI system has three components: (1) a global model which takes four mammograms and produces a case-level prediction; (2) a detection model which detects bounding boxes of lesions for each view; and (3) a hybrid model which takes as input the features from the last layer of the global model and the bounding boxes from the detection model to produce a score for each bounding box. The final case-level cancer prediction is the maximum score of the bounding boxes for that case. The AI system outputs DICOM images with bounding boxes with scores above the operating point shown; however, case-level or bounding box scores are not displayed to the user. Data from 76,142 women (63,918 from the UK, 12,224 from the USA) were used to train the AI tool. Among all the studies, 88.7% were with Hologic images, 9.6% GE images, 0.9% Siemens images and 0.8% Philips images. The exclusion criteria of the AI tool include technical recalls, cases containing more or less than four images and implants. The four-image limitation is due to design of the AI tool where it processes one image for each of the four mammogram views (that is, left craniocaudal, left mediolateral oblique, right craniocaudal and right mediolateral oblique) for a complete analysis (no missing view allowed) and, when multiple images of the same view are present, it defers the selection of that image to the operator.
Readers
Nine radiologists from center 1 and nine radiologists and four consultant radiographers from center 2 participated in the reader study. All were NHSBSP-accredited mammography readers, with between 3 years and 36 years of experience (mean = 13.5 years) and reading between 2,300 and 15,000 examinations per year (mean = 6,000). Only one reader had experience in using AI previously.
Reader training
All readers were provided with an information pack and completed a consent form before the study. All readers completed training in interpreting the AI tool. This was provided by the AI vendor to mimic what would happen clinically and included a 10-min video explaining the AI tool and 100 cases that showed the AI decision and the ground truth—cancer or no cancer—and the location of any cancers. These training cases were from a screening center not included in the study. In addition a pilot study was performed by the research team. This included 28 cases, to train the readers in how to use the viewing software (RiViewer) and to test the entire process before the main study, including paperwork generation, hanging protocol, clarity of questions asked and timing. There was no overlap between the pilot study cases and the cases used in the main study.
Study paperwork
Clinically, when making arbitration decisions, the arbitration panel can view the decisions of the first and second readers on the NBSS and the clinical paperwork, where the readers have written their opinion and/or drawn areas of suspicion on a diagram. It was not possible to show the readers in this study the original paperwork or NBSS because this would show the original arbitration decision and the data would not be anonymized. To overcome this, research radiographers laboriously transcribed the original first and second reader opinions and diagrams of suspicious regions to create an anonymized copy of the study paperwork blinded to the screening outcome. For cases in the human arm, the study paperwork contained the opinions of both first and second readers. For cases in the AI arm, the study paperwork contained only the first human reader opinion (the second reader is AI).
Arbitration reading conditions and hanging protocol
Batches of ten cases for arbitration were reviewed by pairs of readers. As these sessions were outside of working hours, the pairing depended primarily on working patterns. This mimics the clinical situation, where readers working at the same time arbitrate together. The pairs were not fixed, to allow for flexibility around clinical and personal commitments. The pair reading each batch was recorded. The reading took place on clinical workstations at the screening center using RiViewer software in a reading room with normal clinical conditions, including low lighting and high-resolution monitors.
The proportion of AI arm and human arm cases within a batch was based on the proportion in the entire dataset at that center. The readers saw the study images (termed ‘current images’), the images of the immediately prior screening round if there was one and, for the AI arm, the images produced by the AI model with any areas of concern annotated. For both arms, the paperwork was shown after the readers had looked at the current images and prior images. For the AI arm, the study paperwork was shown at the same time as the AI images, so that, for images in the AI arm, the readers saw the human and AI decisions at the same time. For both arms, the readers had to complete a whole loop of a defined hanging protocol before they could make a decision for that case. It was not possible to blind the AI arm to the readers because the AI output was overlaid on images and the human readers’ decisions on paperwork. However, this is clinically realistic because it is how the images would be read clinically
For all cases readers were asked to provide the Royal College of Radiology 5-point scale M-score25 (M1, no recall; M2, no recall; M3, recall; M4, recall; and M5, recall) for each breast, and the breast density Breast Imaging Reporting and Data System (BIRAD) categories A–D. For cases with prior imaging, they were asked additionally whether the priors changed their recall decision. For cases in the AI arm, they were also asked whether they were satisfied with the AI assessment of the case. If recalling a case, the reading pairs were asked to draw a bounding box around the areas being recalled and provide the conspicuity, lesion type and suspicion of malignancy. The readers were asked to draw a rectangle around the region in both views. Each region has an ID and, if they saw it in both views, they linked the region with the same ID.
Data quality control
Collection of all clinical data and images was automated and the images and data fields were not altered during collection. This ensured that the data were clinically relevant and representative. The reader study required study paperwork to be transcribed from clinical paperwork by research radiographers. The trial manager checked that the clinical paperwork had been correctly transcribed for 1% of the study paperwork during on-site monitoring. The data entered by the readers from the reader study were checked fortnightly with automated scripts, for any inconsistencies or incomplete data. These data checks were outlined in a data management plan at the start of the study.
Exploratory human factor surveys
Participants completed online surveys before, during and after the study. This included relevant questions from the NASA Task Load Index26, trust and general impressions of the AI tool. Results in this paper are shown for the surveys after the study.
Positive and negative definitions used in the analysis
Positive cases
A positive case is a woman diagnosed with cancer within 39 months of the screening mammogram used in the study, based on pathological information. This therefore includes screen-detected cancers, interval cancers and screen-detected cancers detected at the next screening round.
Negative cases
A negative case is a woman whose mammograms used in the study resulted in an outcome of normal, with routine recall to screening 3 years later and the follow-up mammograms from 24 months onward also resulted in an outcome of normal with routine recall to screening 3 years later (age <68 years only)
Localization ground truth
The mammograms of all the positive cases were annotated by expert radiologists or consultant radiographers who did not participate in the study. They drew a rectangular ROI tightly around each lesion. They then described the radiological appearance of the lesion (mass, distortion, asymmetry, calcification), whether the lesion was malignant or benign and the conspicuity of the lesion on a three-point scale (very subtle, subtle or obvious). Conspicuity was defined as how visible the lesion was in the image, in the annotator’s judgment. For interval cancers and next-round cancers, the cancer was annotated on the diagnostic image (where available) and, in addition, the location the cancer would have been as annotated in the prior image.
Statistics and reproducibility
Study characteristics
Descriptive analysis was used to summarize study population characteristics. Frequencies and percentages were calculated for categorical data. A χ2 test was used to compare proportions of characteristics between included and excluded groups.
Primary analysis
Our primary endpoint was noninferiority (prespecified 5% absolute margin) of the AI arm for sensitivity and specificity at the case level, compared to the human arm, measured against a 39-month ground truth. Statistical testing was performed using one-sided tests at the 0.025 significance level (after correcting for multiple comparisons using Holm–Bonferroni). CIs on the difference were Wald’s intervals27 and Wald’s test was used for noninferiority28. Both used Obuchowski’s variance estimate29. If noninferiority was shown, a one-tailed superiority test was planned to follow without loss of power or requirement for multiple testing30,31. Superiority comparisons were conducted using Obuchowski’s extension of the two-sided McNemar’s test for clustered data. Clusters were defined to group arbitrations read by the same reader pair. For case-level analysis the highest RCR M score for each breast was used. The data met the requirements of the paired binary tests used (Wald’s and McNemar’s tests).
Secondary analysis
Case-level secondary analysis included positive predictive value (PPV), negative predictive value (NPV), cancer detection rate (CDR) and recall rate (RR). For PPV and NPV, CIs on the absolute values, differences and CIs on difference were calculated by bootstrapping. For CDR and RR, differences were calculated using Obuchowski’s extension of the two-sided McNemar’s test for clustered data. For CDR and RR, Wald’s CIs were calculated with Obuchowski’s clusters based on reader pairs.
Exploratory analysis
Case-level subgroup sensitivity and specificity were calculated by type of screen, age, ethnicity, X-ray system manufacturer, IMD and breast density. In addition, subgroup sensitivity was calculated by cancer type, cancer grade, lesion characteristic and lesion size.
The age was taken from the NBSS. The grouping of age (50–54 years, 55–59 years, 60–64 years, 65–70 years) used as subgroups was as reported in published NHSBSP statistics. The ethnicity was taken from the NBSS. The grouping of ethnicities (white, mixed, Asian, black, other, not specified) as subgroups was based on the NHS Data Dictionary ethnic categories (https://www.datadictionary.nhs.uk/data_elements/ethnic_category.html). The IMD 1–10 (as defined in https://www.gov.uk/government/statistics/english-indices-of-deprivation-2019) was calculated from lower layer super output area data before de-identification. Breast density values (BIRADS 1–4) were calculated for mammograms acquired using Hologic devices with software developed by Royal Surrey32. The breast density subgroups were the categories from BIRADS, 5th edn. X-ray manufacturer values (Hologic and Siemens) were taken from the DICOM header of the mammography images. The screen type (first or subsequent screen) was taken from the NBSS. The subgroups used were as in NHSBSP statistics. The cancer type (invasive or in situ) was taken from the NBSS. These subgroups are reported in published NHSBSP statistics. The invasive grades (1, 2 and 3) and in situ grades (low, intermediate and high) were taken from the NBSS. The subgroups were based on the NHS Data Dictionary tumor grades for breast screening (https://archive.datadictionary.nhs.uk/DD%20Release%20June%202023/attributes/tumour_grade_for_breast_screening.html). The lesion type was obtained by an expert radiologist annotating the cancers; if that was not possible due to the diagnostic images not being available, the lesion type was taken from the NBSS. The invasive lesion size (small, <15 mm, and large, ≥15 mm) was taken from the NBSS. The subgroups used were as in NHSBSP screening statistics.
As the study was not powered for subgroup analysis and there were no prespecified subgroup endpoints, these subgroup analyses should be considered exploratory and hypothesis generating. We therefore present unadjusted CIs for subgroup differences to describe observed trends and magnitudes of effect within subgroups. It is important to note that these CIs should be interpreted cautiously due to the lack of power and the increased risk of false-positive findings associated with multiple subgroup comparisons. No formal hypothesis testing or multiplicity adjustments were conducted for these exploratory subgroup analyses. Case-level CIs were calculated using Wald’s CIs for groups of >50 cases and, for groups of <50 cases, bootstrapping was used.
Finally, localization analysis of the bounding boxes drawn during arbitration was performed using the RJafroc package v2.1.2 in RStudio v4.3.3 (ref. 33). A correctly localized lesion was defined as the overlap between the ROI drawn at arbitration and the corresponding ground-truth ROI having an intersection over union value ≥0.1. All intersections over union values <0.3 were reviewed by a radiologist who did not participate in the reader study and the hit-or-miss decision was changed accordingly.
For human factor analysis, perceived task load differences for the human and AI arm were analyzed using Wilcoxon’s signed-rank test. Other questions, such as those on trust and general impressions, were examined using descriptive statistics for closed-ended questions and open-ended responses underwent dual-coder thematic analysis.
Post-hoc analysis
For all positive cases where the AI correctly recalled but human arbitration then overrode the decision, we checked whether the AI ROI had correctly localized the ground-truth ROI. In addition, the average number of false-positive prompts per case were calculated for: all cases, positive cases, negative cases and positive cases where the AI correctly recalled but human arbitration then overrode the decision. For the positive cases, 2 × 2 tables of outcomes for the human and AI arms were provided for all positive cases (Supplementary Table 1), screen-detected cancers only (Supplementary Table 2) and negative cases only (Supplementary Table 3).
Sample size estimation
We powered the study by simulating a two-arm, within-case design (routine versus AI assisted), where each case is read under both regimens and the primary analysis is a matched-pair Wald’s test for noninferiority on sensitivity (specificity was expected to be amply powered, given the low prevalence). We assumed identical underlying performance in both arms: latent continuous scores with area under the curve of 0.90, binarized at a common threshold to yield 73% sensitivity and specificity using 39-month outcomes9. Between-arm correlation was modeled via an agreement parameter set to 84.5%, matching previously observed R1–R2 concordance on positives. We modeled the two site-specific arbitration protocols (R1 | R2 and R1 ≠ R2) and powered the study using a worst-case scenario that combined the R1 | R2 arbitration style, consensus panel recall of 0.73 and agreement between arms of 0.70. Under these assumptions, 275 cancer-positive cases exceeded 90% power, whereas 200 positives provided 80% power. We therefore targeted a minimum of 200 positive cases per site to achieve 80% power. Assuming a population prevalence of cancer, this corresponded to 25,000 cases per site.
Reproducibility
Randomization is not applicable to this study because it was a retrospective study and all clients were in both arms of the study. As described above, it was not possible to blind the AI arm to the readers because the AI output was overlaid on images and the human readers’ decisions on paperwork. However, this is clinically realistic because it is how the images would be read clinically. The data met the requirements of the paired binary tests used (Wald’s and McNemar’s tests). The data exclusions were defined before the study. From the 50,000 women, 4,354 (8.7%) were excluded due to being within the AI exclusion criteria (technical recalls, cases containing ≥4 or ≤4 images and implants) and 44 (0.1%) cases were excluded due to insufficient or conflicting clinical information.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.


