Author(s): Vahe Sahakyan
Originally published on Towards AI.

So far in this series, we designed systems with predefined structure.
We defined the execution flow.
We separated reasoning from revision.
We controlled when research happens.
Even when loops were introduced, the workflow remained bounded and predictable.
However, some problems cannot be fully decomposed in advance.
You may not know how many tool calls will be required.
You may not know what information is needed until you see the result of the previous step.
In these cases, a fixed plan is not enough.
The system must reason and act step by step, adapting as new information arrives.
This article introduces ReAct — a control pattern where reasoning and tool use are interleaved inside a feedback loop.
Introduction — When the Plan Cannot Be Defined Upfront
Consider a query such as:
“What’s the current stock price of Tesla, and is it a good time to buy based on recent trends?”
This is not a single-step task.
To answer it properly, the agent must retrieve the current stock price, examine recent performance, interpret the trend, and decide whether more data is needed before reaching a conclusion.
The difficulty is that the number of steps cannot be determined in advance. The first search may reveal volatility. That may require additional context. New information may change the direction of the analysis.
In this type of problem, the next step depends on the result of the previous one.
A single generation pass is not sufficient.
A fixed draft–revise cycle is not sufficient.
A separate research phase triggered after critique is not sufficient.
Instead, reasoning and tool use must proceed together.
In the ReAct pattern (Reasoning + Acting), the model does not generate a complete plan before interacting with tools. It reasons about the current state, decides on an action, observes the result, and then reasons again. The process continues until enough information has been gathered.
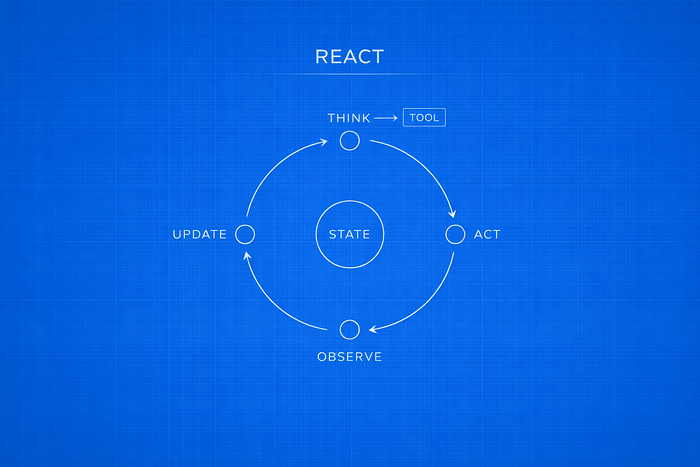
The control flow follows a loop:
Reason → Act → Observe → Reason → … → Stop
The answer is constructed incrementally, with each observation influencing the next step.
What Is ReAct?
ReAct stands for Reasoning + Acting.
It is a control pattern where reasoning and tool use happen inside the same loop.
Unlike Reflection or Reflexion, ReAct does not separate thinking and execution into phases. There is no full draft first. There is no dedicated research phase after critique.
Instead, the system moves step by step.
The core loop looks like this:
Thought → Action → Observation → Thought → … → Stop
Here is what each step means:
Thought
The model reviews the current state and decides what to do next.
Action
If more information or computation is needed, the model calls a tool. This could be a web search, a calculator, a database query, or another function.
Observation
The result of that tool call is returned and added to the state. The model then reasons again using the updated context.
The loop continues until the model produces an answer without requesting another tool call. At that point, execution stops.
This pattern is different from revision-based approaches.
In Reflection, the model improves a completed answer.
In Reflexion, research happens after critique.
In ReAct, there is no complete answer at the beginning. The answer is built step by step as the model interacts with tools.
As a result:
- The number of steps is not known in advance.
- Tool calls are decided during execution.
- Each reasoning step depends on the latest observation.
ReAct treats tool results as part of the reasoning process, not as a separate phase.
Control Structure of ReAct
ReAct is more than combining an LLM with tools. The key idea is how the loop is organized.
In earlier patterns:
- Sequential pipelines followed a fixed path.
- Reflection added an internal revision loop.
- Reflexion added a separate research step.
ReAct removes those fixed phases. Instead, reasoning and tool use happen inside the same loop.
Each cycle looks like this:
- The model reasons about the current state.
- It decides whether to call a tool.
- The tool returns a result.
- The model reasons again using the updated information.
The next step depends on what was just observed.
Several properties follow from this structure:
- The full plan is not known at the beginning.
- The state grows over time as observations are added.
- Tool calls are used to gather missing information.
- The loop stops when the model produces an answer without requesting another tool.
In ReAct, there is no predefined execution path. The sequence of steps emerges during execution.
Difference from Reflexion
ReAct and Reflexion both use tools, but they use them in different ways.
Reflexion
Reflexion is a step-by-step process with separate phases:
- Draft an answer
- Critique the draft
- Run research
- Revise using the results
Research happens after critique, and tool calls usually occur in a dedicated research step.
The flow looks like:
Draft → Research → Revise
ReAct
ReAct does not start with a full draft. Instead, reasoning and tool use happen in a loop:
Think → Act → Observe → Think → …
There is no separate research phase. Each tool result directly affects what the model does next.

Difference from Orchestration
ReAct can look similar to orchestration because both involve multiple steps and tool use.
The difference is how those steps are decided.
Orchestration
In orchestration:
- A planner breaks the task into subtasks at the beginning.
- The system builds a task graph based on that plan.
- Workers execute the defined subtasks.
Even if the number of subtasks depends on the input, the decomposition happens before execution begins. The overall structure is defined first, and then work is carried out.
The flow is plan-first, then execution.
ReAct
In ReAct:
- There is no full plan at the beginning.
- The system decides the next step only after seeing the result of the previous one.
- The number of steps is not known in advance.
The process unfolds step by step inside a loop.

Orchestration works well when the task can be decomposed before starting.
ReAct is better suited for problems where the next step depends on what was just observed.
Minimal ReAct Workflow
At its simplest, a ReAct agent is a loop between two nodes:
- A model node that reasons and may request a tool
- A tool node that executes the request and returns an observation
Minimal State
The system keeps a running list of messages: user input, model responses, and tool outputs.
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
This state grows over time. Each tool result becomes part of the context for the next reasoning step.
Model Node (Reasoning Step)
The model reads the current state and produces the next message. That message may include a tool call.
def call_model(state: AgentState):
response = model_react.invoke({"scratch_pad": state["messages"]})
return {"messages": [response]}
If the model returns a normal answer, execution stops.
If it includes a tool call, control moves to the tool node.
Stop Condition
The loop continues only when the model requests another tool call.
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
If no tool call is present, the workflow ends.
If a tool call exists, the loop continues.
Loop Wiring
The feedback loop is defined in the graph:
workflow = StateGraph(AgentState)workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.add_edge("tools", "agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END,
},
)
workflow.set_entry_point("agent")
graph = workflow.compile()
This wiring creates the ReAct cycle:
- The agent reasons.
- If a tool is requested, it runs.
- The result is added to the state.
- Control returns to the agent.
The loop continues until the model produces an answer without requesting another action.
There is no predefined number of steps and no separate research phase. The number of iterations depends on how many tool calls are needed.
State Accumulation
ReAct works because the agent does not restart reasoning at every step.
Each tool result is added to the same shared state. That updated state is then used in the next reasoning step.
The message history becomes a running record of:
- The original question
- The model’s intermediate reasoning
- The tool calls it made
- The observations returned by those tools
Because all of this remains in context, the agent can build its answer gradually.
In a single-step system, reasoning happens once.
In Reflexion, revision happens in separate phases.
In ReAct, reasoning continues over multiple steps. Each cycle adds new information instead of replacing the previous result.
This accumulated state allows the agent to handle tasks that require several tool calls and adjustments along the way.
When ReAct Is Appropriate
ReAct is not the default choice. It is useful for tasks where the next step depends on the result of the previous one.
Use ReAct in the following situations:
1. The Number of Steps Is Unknown
If a task cannot be broken into a fixed sequence in advance, a loop works better than orchestration.
When the agent cannot predict how many tool calls are required, it needs to decide step by step.
2. Information Must Be Discovered Gradually
Some questions require exploration instead of a single search.
Examples include:
- Real-time financial analysis
- Multi-step research across different sources
- Queries where each result determines the next query
In these cases, one research phase is not enough. The system must evaluate each result before deciding what to do next.
3. Tool Results Affect Future Decisions
ReAct is useful when tool outputs change what the agent should investigate next.
If a search result introduces new questions or changes direction, the system needs to reason again before taking another action.
4. Strategy Must Change During Execution
ReAct assumes the agent does not have full information at the start.
If the system must adjust its approach as new data arrives, a step-by-step loop is more appropriate than a fixed plan.
When ReAct Is Not Needed
ReAct is usually unnecessary for:
- Direct factual questions
- Tasks that can be solved in a single reasoning pass
- Problems where a clear plan can be defined before execution
ReAct is most useful when the system must gather information gradually and adjust its next step based on what it learns.
Where ReAct Breaks
ReAct is flexible, but that flexibility introduces trade-offs.
1. Latency
Each iteration may include a tool call. Every tool call adds network delay and model inference time.
Unlike Reflection or Reflexion, where the number of phases is usually limited, ReAct does not have a fixed execution length. Total runtime depends on how many steps are taken.
2. Token Growth
Because the message history grows over time, context size increases with each step.
More steps mean more tokens. This increases both cost and memory usage.
If the loop runs too long, it becomes expensive.
3. Variable Execution Length
There is no predefined number of steps.
Two runs of the same query may:
- Use different numbers of tool calls
- Follow slightly different paths
- Stop at different points
This makes performance and cost less predictable.
4. Tool Quality
ReAct depends heavily on tool outputs.
If a tool returns incorrect or incomplete data, the model may base later decisions on that faulty information. Since each step builds on previous results, early mistakes can affect the final answer.
5. Unbounded Loops
Without limits, the agent may continue requesting tools indefinitely.
Termination rules must be defined explicitly, such as:
- Stop when no tool call is produced
- Stop after a maximum number of iterations
Without these limits, the loop may run longer than intended.
ReAct works best when step-by-step exploration is necessary. However, it requires clear limits on iteration, cost, and tool usage to remain efficient and manageable.
Big Picture — From Determinism to Adaptive Control
Throughout this series, the model stayed the same.
What changed was the control structure around it.
Each pattern added a new capability — not by making the model smarter, but by changing how the system handles uncertainty.
Here is the progression:

The main difference across these patterns is how the system reacts to new information.
- Sequential systems follow a fixed path.
- Reflection improves an answer after it is generated.
- Reflexion adds research when knowledge is missing.
- ReAct adjusts its next step based on what just happened.
The model itself does not change.
What changes is how tightly reasoning is connected to feedback from the environment.
As the patterns progress, the system moves from fixed execution to step-by-step decision making.
The goal is not to increase model intelligence.
The goal is to design control structures that match the level of uncertainty in the task.
Final Closing Statement
Large language models are powerful, but power alone does not create agent behavior.
What creates agent-like systems is the control structure around the model.
Across this series, we examined how different control patterns change system behavior:
- Structure determines how work flows.
- Structure determines how answers are revised.
- Structure determines when research is triggered.
- Structure determines how decisions are made step by step.
The model itself did not change.
What changed was how reasoning was organized — whether it followed a fixed path, looped for revision, incorporated external research, or adapted step by step through tool interaction.
Using tools is not enough to build capable agents.
What matters is how reasoning, feedback, and execution are structured and controlled.
Published via Towards AI


